Requesting GPUs
Jobs that will utilize ICER's GPU resources must request these devices through SLURM. This page will cover the nuances of GPU resource requests and how those requests relate to CPU and memory requests.
Basics of GPU Requests
GPUs may be requested using the --gpus (or -G) option within a batch script or on the
command line when using sbatch or salloc.
At minimum, users must specify the number of GPUs they want to request. Due to the various generations of GPUs available on the HPCC, ICER strongly suggests that users also specify the type of GPU. This is because your software may be compiled for a specific GPU architecture.
Software that can run on GPUs will still need a CPU to manage the GPU. Unless you know that your software can take advantage of multiple CPUs while also using one or more GPUs, you should only request one CPU for this purpose. Additionally, be sure your software can utilize multiple GPUs at the same time before requesting more than one GPU.
For example, the following requests one V100 GPU that will be managed by a single CPU:
#SBATCH --ntasks=1
#SBATCH --gpus=v100:1
: that separates the type and number of GPUs. For more on the available types of GPUs, see our page on GPU resources.
GPUs in OnDemand
GPUs can also be selected for Open OnDemand apps. Look for the "Advanced Options" checkbox. Once selected, you should see options for "Node type" and "Number of GPUs". You must set the node type if you wish to select a particular GPU model; for example, "amd20" or "intel18" for the V100 GPUs. Reference the GPU resources page to determine what type of node you should request for each type of GPU. SLURM will be unable to schedule your job if you request more GPUs than are present on that type of node.
Memory & GPUs
GPU's have their own memory (sometimes referred to as Video Random Access Memory or VRAM) that is separate from the RAM used by the CPU. The name VRAM follows from the origin of GPUs as dedicated graphical rendering hardware and does not imply any restrictions on the type of data a GPU can process.
Each of the GPUs available on the HPCC have varying amounts of VRAM as seen in our hardware resource tables. Requesting a GPU through SLURM will automatically give you access to all of its VRAM. This is in contrast to CPU RAM, which you must explicitly request through SLURM.
For example, the SLURM option --mem-per-gpu will request a certain amount of CPU memory per GPU requested. The following settings will request a total of 6GB of CPU RAM, 3GB for each of the two GPUs requested:
#SBATCH --ntasks=1 # number of CPUs
#SBATCH --gpus=v100:2 # number of GPUs
#SBATCH --mem-per-gpu=3G # memory for CPUs
--mem (total memory) and --mem-per-cpu are mutually exclusive with --mem-per-gpu.
Utilizing Multiple GPUs
Some software is able to utilize multiple GPUs. These GPUs may be managed by one or more CPUs depending on how the software was written. Make sure you understand your software's capabilities and limits before requesting multiple GPUs and/or CPUs at the same time; otherwise, these resources will remain idle but still count against your yearly usage limits.
One CPU for Multiple GPUs
Most software that can utilize multiple GPUs will still use a single CPU to manage them. This means that the total number of GPUs your software can utilize is restricted by the number of GPUs on one node. See our table on GPU Resources for a reference.
This arrangement can be visualized with the following diagram. The user has requested a single CPU and four GPUs, shown in blue. The single CPU communicates instructions and data with all of the allocated GPUs. Since the hypothetical node in this diagram only has four GPUs, the user can only use a maximum of four GPUs at a time on this type of node.
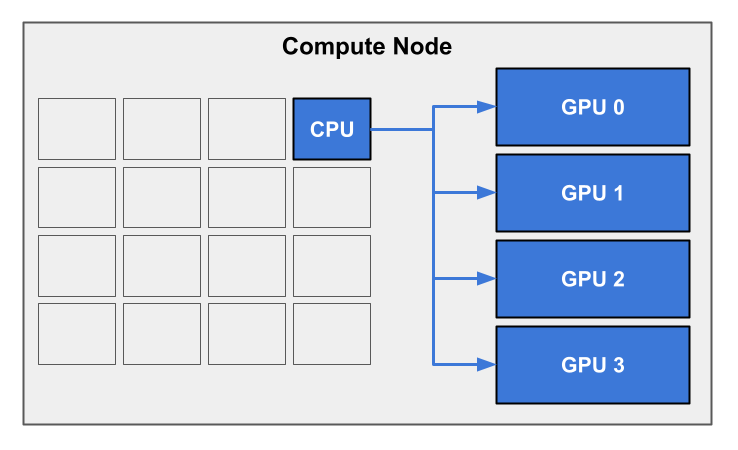
Requesting this kind of configuration is straightforward:
#SBATCH --ntasks=1
#SBATCH --gpus=v100:4
Multiple CPUs for Multiple GPUs
It's possible for multiple CPUs to manage a set of GPUs when using multiple processes. The most common way to achieve this is by using MPI. Each MPI process can manage one or more GPUs while also communicating with other processes. With the addition of MPI, the software is no longer restricted by the number of GPUs on a node.
One possible configuration for this is represented in the diagram below. In this diagram, each node has one CPU managing two GPUs. The two CPUs are able to communicate with each other via MPI (gray arrows).
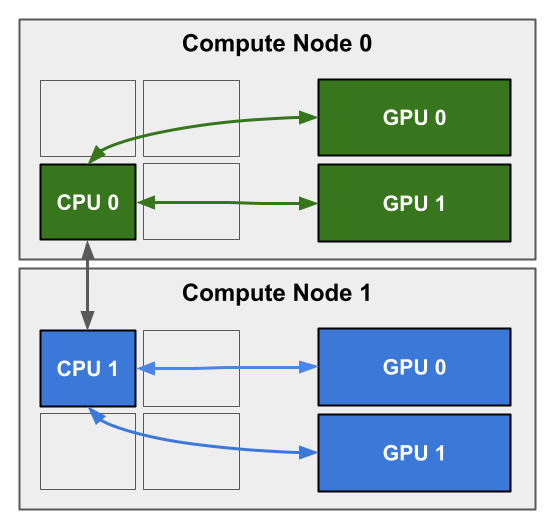
The best way to request this kind of configuration is to use the --gpus-per-node option:
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=1
#SBATCH --gpus-per-node=v100:2
Another option is to have each MPI process manage only one GPU, as diagrammed below. Each of the four CPUs manages a GPU of the same color. These CPUs are also able to communicate with each other via MPI (gray arrows).
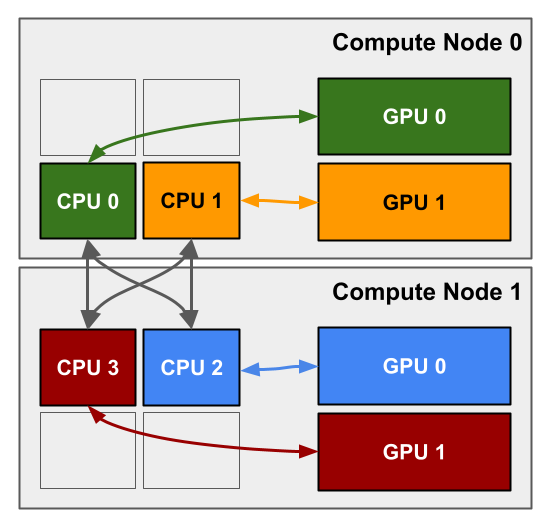
The optimal way to request this configuration is to use the --gpus-per-task option:
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=2
#SBATCH --gpus-per-task=v100:1
CPU/GPU Hardware Locality
The hardware on all GPU nodes, except for the Grace Hoppers, is configured such that GPUs have a high-speed link to select CPU cores; the Grace Hopper nodes have a high-speed link to all CPU cores. By default, the scheduler looks for any available CPU cores on a GPU node to fulfil a resource request for a job, allowing a job to start sooner than if it had to wait for the CPU cores with a high-speed link to the an available GPU.
Certain workloads can be sensitive to running on CPUs that do not have this high-speed link to the allocated GPU. To ensure a job is allocated only CPUs with a high-speed link to the allocated GPU, the --gres-flags option must be set accordingly:
#SBATCH --gres-flags=enforce-binding
The following table details these limits for each node type.
| Node Type | GPU Type | Cluster | Maximum CPUs per GPU with --gres-flags=enforce-binding |
|---|---|---|---|
| nvl | v100 | intel18 | 20 |
| nvf | v100s | amd20 | 24 |
| nal | a100 | amd21 | 16 |
| nif | a100 | intel21 | 32 |
| nch | gh200 | arm23 | 72 (All CPUs) |
| neh | h200 | amd24 | 8 |
| nfh | h200 | amd24 | 8 |