Compilers and Libraries
The HPCC organizes most compilers and libraries into "toolchains". A toolchain is a set of tools bundled together that can be used to build software. This may be as minimal as a single compiler, or as expansive as a compiler with MPI, linear algebra, CUDA, and other helpful libraries.
These toolchains are inherited from the program ICER uses to build much of its software, EasyBuild. For more information, please see the EasyBuild documentation pages for common toolchains and all toolchains.
Common toolchains
ICER primarily supports two toolchains on the HPCC: foss and intel. These
are each numbered by year (with an a or b suffix for midyear and end of
year releases respectively) and contain compilers and libraries that are
compatible with each other.
foss toolchain
foss components
The foss toolchain is currently derived from the following components (and is
equivalent to doing a module load on each one individually):
GCC: Composed ofOpenMPI: MPI implementation for multi-process programsFlexiBLAS: BLAS and LAPACK API (usingOpenBLASand referenceLAPACKas backends) for linear algebra routinesFFTW: Library for Fast Fourier TransformsScaLAPACK: Parallel/distributed linear algebra routines
foss versions
To see the versions of this toolchain available on the HPCC use
module spider foss
and to see the versions of each component, use
module show foss/<version>
foss usage examples
module load foss/2022a
gcc foo.c -o foo \
-fopenmp \ # For OpenMP
-lflexiblas \ # For BLAS/LAPACK
-lfftw3 # For FFTW
./foo
module load foss/2022a
gfortran foo.f90 -o foo \
-fopenmp \ # For OpenMP
-lflexiblas \ # For BLAS/LAPACK
-lfftw3 # For FFTW
./foo
module load foss/2022a
mpicc foo.c -o foo
srun ./foo # Use srun for better SLURM integration instead of mpirun
module load foss/2022a
mpifort foo.f90 -o foo
srun ./foo # Use srun for better SLURM integration instead of mpirun
foss sub-toolchains
If the entire foss toolchain has too many dependencies for your needs,
consider one of the sub-toolchains:
GCC: composed ofGCCCorebinutils
gompi: composed ofGCCOpenMPI
Or feel free to load the individual modules that you need by themselves.
intel toolchain
intel components
The intel toolchain is currently derived from the following components (and
is equivalent to doing a module load on each one individually):
intel-compilers: Intel's set of (classic and oneAPI) C/C++ and Fortran compilers in addition to:impi: Intel's MPI implementation for multi-process programsimkl: Intel's BLAS and LAPACK implementations with FFT and other math libraries
intel versions
To see the versions of this toolchain currently available on the HPCC use
module spider intel
and to see the versions of each component, use
module show intel/<version>
intel usage examples
module load intel/2022b
icx foo.c -o foo \
-qopenmp \ # For OpenMP
-qmkl # For BLAS/LAPACK/FFT
./foo
module load intel/2022b
ifx foo.f90 -o foo \
-qopenmp \ # For OpenMP
-qmkl # For BLAS/LAPACK/FFT
./foo
module load intel/2022b
mpiicc foo.c -o foo
srun ./foo # Use srun for better SLURM integration instead of mpirun
module load intel/2022b
mpiifort foo.f90 -o foo
srun ./foo # Use srun for better SLURM integration instead of mpirun
intel sub-toolchains
If the entire intel toolchain has too many dependencies for your needs,
consider one of the sub-toolchains:
intel-compilers: composed ofGCCCorebinutils- The Intel compilers themselves
iimpi: composed ofintel-compilersimpi
Or feel free to load the individual modules that you need by themselves.
Mix and match
Certain components can be combined across toolchains. A notable example is the Intel Math Kernel Library (MKL), imkl, that can be loaded with any other compiler.
C example mixing GCC and MKL
module load GCC/11.3.0
module load imkl/2022.2.1
gcc foo.c -o foo \
-lmkl_rt # MKL single dynamic library
./foo
For more information on linking against MKL, see Intel's documentation.
Alternative compilers and toolchains
In addition to the foss and intel toolchains, select versions of other
compilers are available (with limited support) including:
AOCC
AMD optimized compilers for C and Fortran.
These use LLVM as a backend and therefore have the same command-line syntax as
Clang.
See also the documentation for Optimizing for AMD CPUs which gives information on installing AOCL, the AMD Optimizing CPU Libraries for AMD optimizations of math libraries, BLAS, FFTW, and others.
module load AOCC/4.0.0
clang foo.c -o foo.out \
-fopenmp # For OpenMP
./foo
module load AOCC/4.0.0
flang foo.f90 -o foo.out \
-mp # For OpenMP
./foo
# Assuming AOCL libraries are installed into $HOME/amd/aocl/4.0
module load AOCC/4.0.0
export AOCL_ROOT=$HOME/amd/aocl/4.0
clang foo.c -o foo.out \
-I${AOCL_ROOT}/include \
-L${AOCL_ROOT}/lib \
-fopenmp \ # Required for multithreaded BLAS
-lflame \ # For LAPACK
-lblis-mt \ # For multithreaded BLAS
-lfftw3 # For FFTW
./foo
# Assuming AOCL libraries are installed into $HOME/amd/aocl/4.0
module load AOCC/4.0.0
export AOCL_ROOT=$HOME/amd/aocl/4.0
flang foo.f90 -o foo.out \
-L${AOCL_ROOT}/lib \
-fopenmp \ # Required for multithreaded BLAS
-lflame \ # For LAPACK
-lblis-mt \ # For multithreaded BLAS
-lfftw3 # For FFTW
./foo
Clang
LLVM-based C compilers. For math libraries like
FlexiBLAS and FFTW, you will also need to load a compatible toolchain.
module load GCCcore/11.3.0
module load Clang/14.0.0
clang foo.c -o foo.out \
-fopenmp # For OpenMP
./foo
module load foss/2022a # Compatible with GCCcore/11.3.0
module load Clang/14.0.0
clang foo.c -o foo.out \
-lflexiblas \ # For BLAS/LAPACK
-lfftw3 # For FFTW
./foo
NVHPC (formerly PGI)
The NVIDIA HPC Software Development Kit. This includes C and Fortran
CUDA-compatible compilers, an OpenMPI implementation, and GPU accelerated math
libraries. It also includes implementations of BLAS and
LAPACK,
but for other CPU math libraries like FFTW, you will
need to load a compatible toolchain.
Note that these compilers are most effective for building software on GPUs.
module load NVHPC/21.9-GCCcore-10.3.0-CUDA-11.4
nvc foo.c -o foo \
-mp \ # For OpenMP
-lblas \ # For BLAS
-llapack # For LAPACK
./foo
module load NVHPC/21.9-GCCcore-10.3.0-CUDA-11.4
nvfortran foo.f90 -o foo \
-mp \ # For OpenMP
-lblas \ # For BLAS
-llapack # For LAPACK
./foo
module load foss/2021a # Compatible with GCC/10.3.0
module load NVHPC/21.9-GCCcore-10.3.0-CUDA-11.4
nvc foo.c -o foo \
-lflexiblas \ # For BLAS/LAPACK
-lfftw3 # For FFTW
./foo
module load foss/2021a # Compatible with GCC/10.3.0
module load NVHPC/21.9-GCCcore-10.3.0-CUDA-11.4
nvfortran foo.f90 -o foo \
-lflexiblas # For BLAS/LAPACK
-lfftw3 # For FFTW
./foo
module load NVHPC/21.9-GCCcore-10.3.0-CUDA-11.4
mpicc foo.c -o foo # Uses NVHPC's OpenMPI
srun ./foo # Use srun for better SLURM integration instead of mpirun
module load NVHPC/21.9-GCCcore-10.3.0-CUDA-11.4
mpifort foo.f90 -o foo # Uses NVHPC's OpenMPI
srun ./foo # Use srun for better SLURM integration instead of mpirun
Alternative MPI implementations
Though we recommend OpenMPI or Intel MPI, older installations of MPICH and MVAPICH2 are available. These are generally only compatible with a single compiler module as they were built on a one-off basis.
You can see the available versions and how to load them with
module spider MPICH
or
module spider MVAPICH2
If OpenMPI, Intel MPI, or the available versions of MPICH and MVAPICH2 will
not work for your needs, please contact us to
discuss alternatives.
Basic Mathematical Library Benchmark
Possibly outdated
This benchmark was run when the AMD EPYC processors were installed (approximately 2020). The results may be outdated due to compiler improvements or hardware changes.
This section shows the results of a basic test of the mathematical
libraries with different compilers on the AMD EPYC Processors (i.e., those in
the amd20 cluster). The test runs many calculations of sine, cosine
and logarithm functions in parallel. Each of the calculations is independent
from the others and finally they get summed up. The test is executed by a C
program written with OpenMP multi-threading and compiled with different
compilers and libraries. Three letters (A, G and I) followed by a digit (1 or
2) are used to specify different tests:
| Letters | First | Second | Digit |
|---|---|---|---|
| A | AMD Compiler | AMD basic mathematical Library | 1: all threads running in one socket |
| G | GNU Compiler | GNU basic mathematical Library (-lm) |
2: threads evenly spread to two different sockets |
| I | Intel Compiler | Intel basic mathematical Library (included in compiler) |
where the letter in the first and second position represents which compiler and basic mathematical library is in use respectively. The performance results are presented in the following figure:
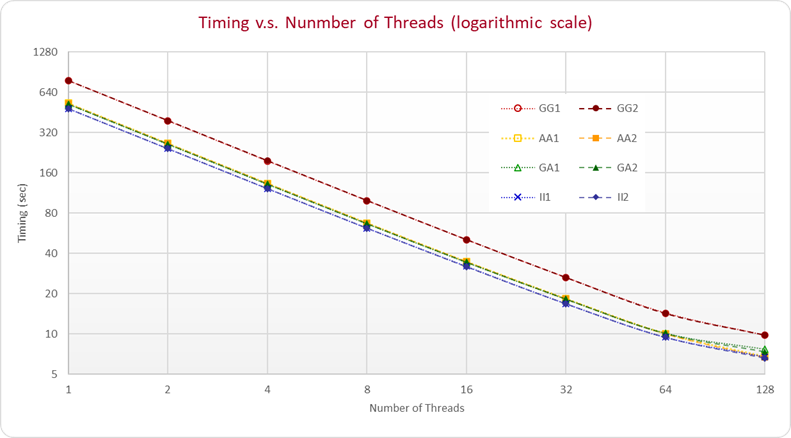
where all timing values were derived by the average of running ten times. As you can see in the figure, the performance of the parallel scaling is almost linear for all compilers and the scaling efficiency is strong (about 61% for AA1 and AA2). From the comparison of the timing results, Intel compiler with its library shows the best performance. However, GCC and AMD compilers with AMD basic mathematical library also perform well. In the results of 128 threads, the elapsed time of AMD compiler with AMD library are very closed to the time of Intel's. In the tests of spreading threads, we also find out all threads running on one socket has no difference from spreading them on two different sockets.
The same C program was also compiled and run on an intel18 and a (now
retired) intel16 node. The timing of amd20 node with 128 threads is about 3
times faster than the performance of intel18 (with 40 threads) and 4.5 times
faster than the performance of intel16 (with 28 threads). The decrease in
timing is well prorated with the increase on thread number.