The HPCC's Layout
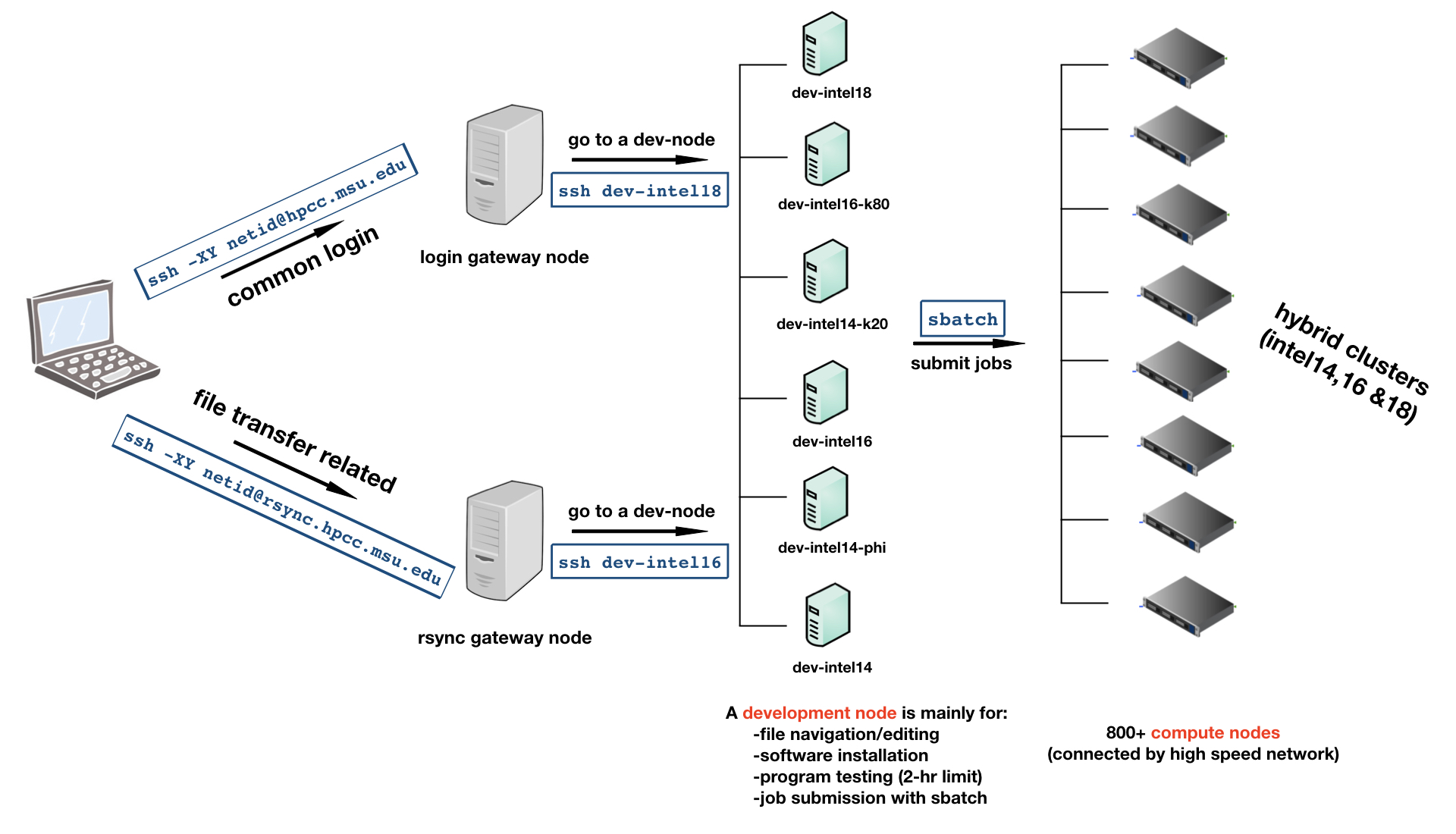
The HPCC is comprised of three different kinds of nodes: the "gateway" entry nodes, development nodes, and compute nodes. In a typical workflow, users will connect to the HPCC through the an entry node, then connect to a development node to compile and test code before submitting jobs to the SLURM queue to be run on a compute node. This workflow is demonstrated in the diagram below.
Each node type is explained in more detail in the following sections. Information on the HPCC's filesystems is available in the filesystem overview.
Entry Nodes
The gateway nodes are the only nodes directly accessible over the internet. Users connect to these nodes from their personal computers using ssh before accessing other parts of the HPCC.
Gateway Nodes
These nodes are the default accessed via ssh <username>@hpcc.msu.edu as in the top fork of the diagram above. The gateway nodes
are not meant for compilig or running software, accessing the scratch space, or connecting
to compute nodes. Users should only use the gateway nodes to ssh to development nodes.
Alternatively, users may set up SSH tunneling to automate the process of passing through the gateway
to a development node.
Development Nodes
From the gateway node, users can connect to any development node to compile their jobs or and run short tests. They may also access files on the scratch file system.
Jobs on the development nodes are limited to two hours of CPU time. More information is available on the development node page.
Each development node is configured to match the compute nodes of the same cluster. If you would like your job to be able to run on any cluster (as is the default for the queue; see the section on Automatic Job Constraints) you should not compile with architecture-specific tuning (e.g. -march or -x).
Warning
Code compiled on different architectures (e.g. amd20 vs intel18) may
have errors when running on other nodes. To avoid this, compile your code
dev-amd20 or specify --constraint=[node type] in your SLURM batch script
where [node type] is the development node type you compiled on. For more
information see our page on Using Different Cluster
Architectures.
Compute Nodes
ICER maintains several clusters of compute nodes. Users submit jobs to the SLURM scheduler which assigns compute nodes based on the resources requested.
A user may see which nodes their job is running on using squeue -u <username>. Not providing a username to squeue will show all jobs currently running on the system. Users may ssh directly to a compute node only if they have a job running on that node. See our page on connecting to compute nodes for more.
Comparison to a personal computer
| Laptop/Desktop | HPCC Clusters | |
|---|---|---|
| Number of Nodes | 1 | 983 |
| Sockets per node | 1 | 2, 4, 8 |
| Cores per node | 4, 8, or 16 | 28, 40, 64, 72, 96, 128 or 144 |
| Cores total | 4, 8, or 16 | 78,844 |
| Core Speed | 2.7 - 5 GHz | 2.5-3.7 GHz |
| RAM (memory) | 8, 16 or 32 GB | 96 GB, 128 GB, 512 GB, 768 GB, 1.5 TB, 2.3 TB or 6TB |
| File Storage | 250, 500 GB or 1TB | 100 GB (Home), 3 TB(Research), 50TB(Scratch) |
| Connection to other computers | Campus ethernet1 Gbit/sec | "Infiniband" 100-400 Gbit/sec |
| Users | 1 | ~4,000 |
| Schedule | On Demand | 24/7 via queue |